Long-context inference makes the KV cache one of the main costs of serving LLMs. During autoregressive decoding, the cache grows with context length, batch size, and model depth. At high batch sizes and long contexts with 100K tokens across dozens of concurrent requests the KV cache consumes a large fraction of GPU memory. Compressing it is a direct way to increase batch size and reduce memory traffic.
The obvious approach is quantization. But pushing KV caches to INT2 (2-bit) precision has been largely impractical. Prior methods either collapse in accuracy or require custom serving layouts incompatible with paged KV-cache systems. Together AI’s OSCAR (Offline Spectral Covariance-Aware Rotation) addresses both problems.
Why INT2 KV Cache Quantization is Hard
KV activations contain channel-wise outliers. A small subset of channels holds extremely large values. Most channels are well-behaved. When you apply INT2 quantization which has only four representable levels and those outliers dominate the scale factor. The quantizer wastes most of its range on rare spikes. Normal values get compressed into just one or two effective levels. This degrades attention quality substantially.
Rotation-based quantization addresses this by applying a fixed orthogonal transform, typically a Hadamard transform, to redistribute outlier energy across all channels. This approach works reasonably well at INT4. At INT2, a deeper problem remains: the rotation is data-oblivious. It can smooth activation ranges, but it does not know which directions the attention mechanism actually reads. Spreading quantization error uniformly is not the same as pushing it into low-importance directions. At INT2, with only four levels, that distinction determines whether the model works at all.

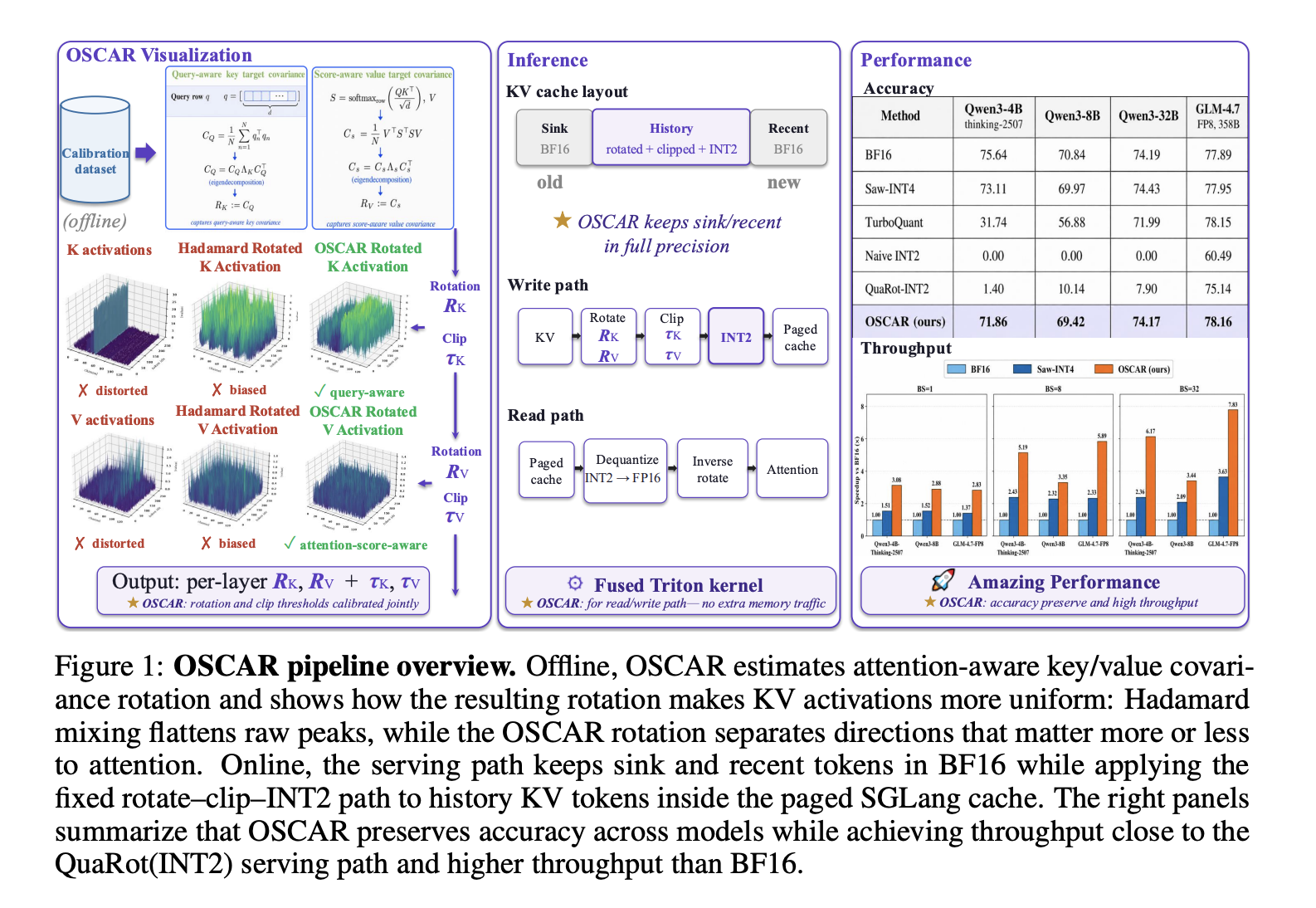
What OSCAR Does Differently
OSCAR’s key observation is that the rotation applied before quantization should be derived from attention statistics themselves — not from the raw distribution of KV activations.
For keys, the downstream error that matters is not the Euclidean reconstruction error of K. It is the error in attention logits. The research team showed this error is: ‖QK⊤ − QK̂⊤‖²F = tr((K − K̂)Q⊤Q(K − K̂)⊤). The weighting matrix is the query covariance Q⊤Q, not K⊤K. Directions where queries have large energy amplify quantization errors in logits. OSCAR estimates the empirical query covariance CQ = (1/N) Σ qn⊤qn from a calibration set, eigen-decomposes it, and uses the eigenvectors UQ as the key rotation basis.
For values, the relevant error is in the attention output SV. This depends on how the attention score matrix S weights each value row. The research team defines the score-weighted value covariance CS = (1/N) V⊤S⊤SV. Directions that remain large after aggregation by S are the ones quantization error propagates through. OSCAR uses the eigenvectors US of CS as the value rotation basis.
The final composed rotations are:
RK = UQ · HHad · PbrRV = US · HHad · Pbr
Each of the three factors addresses a distinct failure mode of per-group low-bit quantization:
- UQ / US aligns channels with attention-importance directions. This diagonalizes the error-weighting matrix so the most important directions are identifiable.
- HHad (Walsh-Hadamard transform) then equalizes channel importance exactly. Lemma 1 in the research paper proves every diagonal entry of HHad⊤ Λ HHad equals tr(Λ)/d — the peaky eigenspectrum exposed by UQ is compressed to a uniform value across all channels.
- Pbr (permuted bit-reversal) reorders channels so that for any power-of-two quantization group size, each group receives one representative from each level of the importance hierarchy.
The research team provides Theorem 1 proving UQ and US are optimal under a frozen-error surrogate objective with diagonal residual assumptions.
The Serving System: Mixed-Precision Cache Layout
OSCAR integrates into SGLang’s production serving stack as an INT2 KV-cache mode with full compatibility with paged attention.
The KV cache layout uses three regions per request:
- Sink tokens (first S0 = 64 tokens): stored in BF16. These function as attention sinks.
- Recent tokens (last W = 256 tokens before current position): stored in BF16.
- History tokens (everything in between): stored as INT2 after OSCAR rotation and clipping.
At 128K context length, the BF16 sink and recent windows represent only 0.24% of total tokens. The ablation (Table 5 in the research paper) shows (S=64, R=256) is the accuracy-efficiency knee: smaller windows noticeably hurt accuracy; larger windows give negligible additional benefit at higher BF16 memory cost.

Write and read paths use fused Triton kernels. On the write path, each token is rotated, clipped to a calibration-derived percentile threshold (typical values: cK = 0.96, cV = 0.92), then quantized with per-token asymmetric INT2 at a default group size of GK = 64 channels per group. On the read path, the INT2 kernel unpacks bytes, dequantizes, inverse-rotates, and passes results to the attention kernel — all in one fused pass without extra memory traffic. The value rotation RV is absorbed into the model’s projection weights offline, eliminating its online compute cost.
Outcome
The research team evaluated OSCAR on four model configurations: Qwen3-4B-Thinking-2507, Qwen3-8B, Qwen3-32B, and GLM-4.7-FP8 (358B parameters). Benchmarks include AIME25, GPQA-Diamond, HumanEval, LiveCodeBench v6, and MATH500, all at 32K maximum generation length.
Accuracy (at 2.28 bits per KV element):
For context on how competing methods compare: naive INT2 (no rotation) scores 0.00 on both Qwen3-4B and Qwen3-8B. QuaRot-INT2 (Hadamard-only rotation) scores 1.40 on Qwen3-4B and 10.14 on Qwen3-8B. TurboQuant at 3.25 bits drops 43.90 points on Qwen3-4B-Thinking. Saw-INT4 at 4.25 bits reaches 73.11 on Qwen3-4B — OSCAR at 2.28 bits reaches 71.86.

The research team also compared against channel-wise methods on AIME25 (Table 1). On Qwen3-8B, OSCAR at 2.38 BPE achieves 66.67±3.33 — above KIVI-KV2* at 57.67 (2.26 BPE) and Kitty at 59.67 (2.39 BPE). Note that channel-wise methods require residual buffers or custom page layouts that do not fit standard paged-attention serving, so this comparison is limited to the single shared benchmark where results were available.
Long-context robustness (RULER-NIAH):
On GLM-4.7-FP8, OSCAR matches the BF16 curve through 128K.
Throughput (H100, 100K context, batch size 1):
Decode throughput speedup relative to BF16, at increasing context lengths:
At batch size 32, job-level throughput at 100K context reaches 6.17× over BF16 on Qwen3-4B-Thinking and 7.83× on GLM-4.7-FP8. The speedup increases with context length because decoding becomes increasingly KV-bandwidth-bound. Reducing KV memory by 8× directly reduces that bottleneck. The online rotation overhead is absorbed into the decode kernels.
Marktechpost’s Visual Explainer
Key Takeaways
- OSCAR quantizes LLM KV caches to 2-bit precision by rotating activations using attention-aware covariance matrices, not generic Hadamard transforms.
- At 2.28 bits per KV element, OSCAR stays within 3.78 points of BF16 accuracy on Qwen3-4B-Thinking while naive INT2 collapses to zero.
- KV cache memory drops approximately 8×, decode speed improves up to 3× at 100K context, and job-level throughput reaches up to 7.83× at large batch sizes.
- Pre-computed rotation matrices for Qwen3-4B/8B/32B, GLM-4.7-FP8, and MiniMax-M2.7 are available in RotationZoo — no recalibration needed.
- OSCAR integrates directly into SGLang with full paged KV-cache and prefix cache compatibility, requiring no changes to the inference client.
Check out the Repo on GitHub, Modelscope and Research Paper. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us